-
메타, 혼합 모달 전단 융합 기초 모델 카멜레온 발표인공지능 2024. 5. 18. 16:50
최근 인공지능(AI) 연구의 중요한 트렌드 중 하나는 멀티모달(multimodal) 모델의 개발입니다. 이러한 모델들은 이미지와 텍스트와 같은 다양한 형태의 데이터를 동시에 처리할 수 있으며, 그 결과 다양한 응용 분야에서 뛰어난 성능을 보여주고 있습니다. Meta AI에서 2024년 5월 16일 발표한 논문 "Chameleon: Mixed-Modal Early-Fusion Foundation Models"의 Chameleon 모델은 이러한 멀티모달 AI의 발전을 한 단계 끌어올린 모델입니다. 이 글에서는 Chameleon의 주요 특징, 기술적 혁신, 성능 평가 및 미래 전망에 대해 심층 분석합니다.
1. Chameleon 모델 개요
Chameleon 모델의 목적
Chameleon 모델은 텍스트와 이미지를 포함한 혼합 모달 데이터를 통합적으로 처리할 수 있는 전 융합 기반의 기초 모델을 제안합니다. 이 모델의 목표는 다양한 작업에서 우수한 성능을 발휘하는 것입니다. 주요 작업으로는 시각적 질문 응답(Visual Question Answering), 이미지 캡션 생성, 텍스트 생성, 이미지 생성, 그리고 장기 혼합 모달 생성(long-form mixed modal generation) 등이 있습니다.
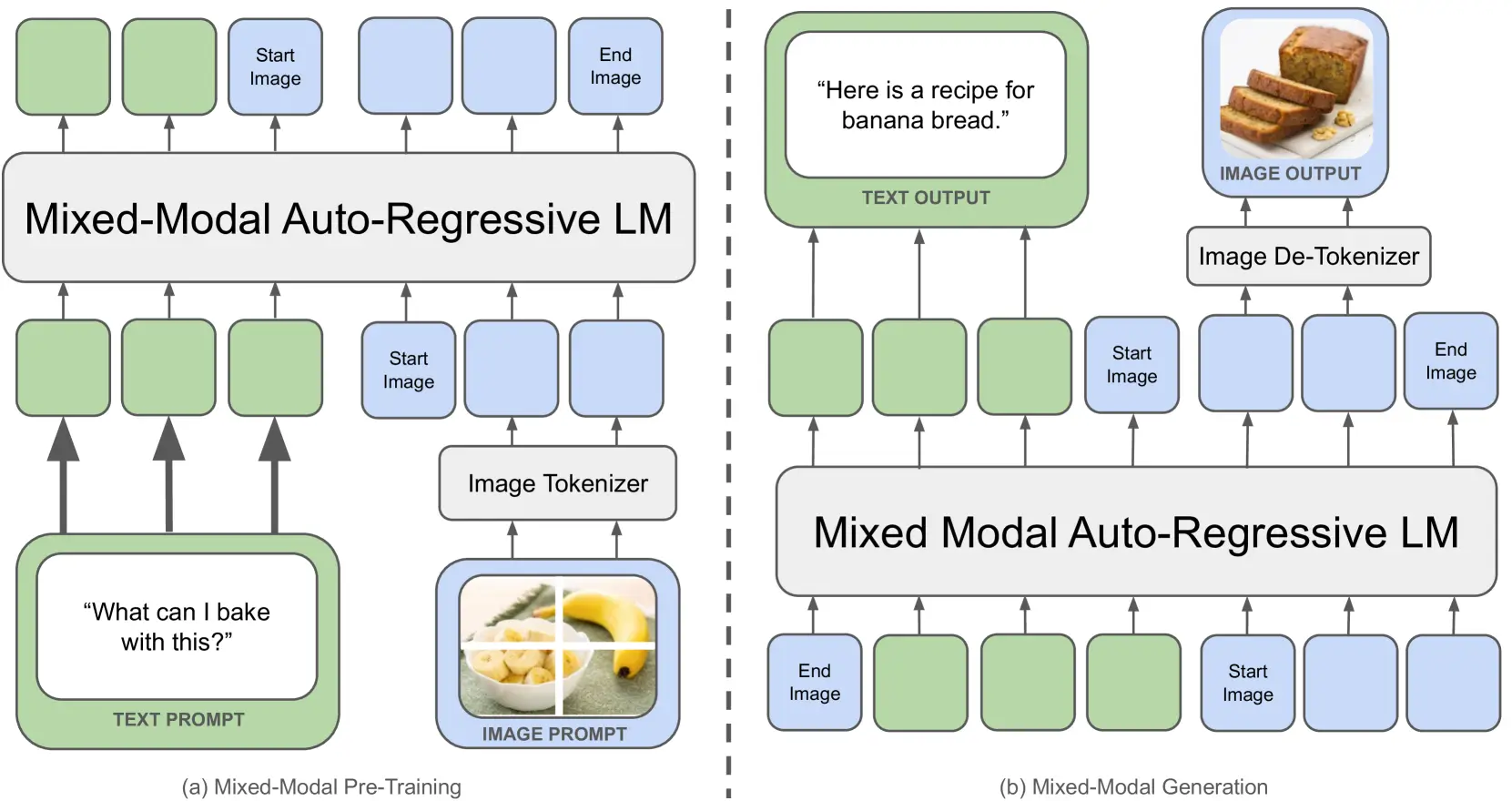
Figure 1. Chameleon represents all modalities 그림 1: 카멜레온은 이미지, 텍스트, 코드 등 모든 모달리티를 개별 토큰으로 표현하며, 처음부터 엔드투엔드 방식으로 학습된 균일한 트랜스포머 기반 아키텍처를 사용합니다. ∼10T 토큰의 인터리빙된 혼합 모달 데이터에 대해 처음부터 엔드투엔드 방식으로 학습합니다. 그 결과, 카멜레온은 임의의 혼합 모달 문서를 추론할 뿐만 아니라 생성할 수도 있습니다. 텍스트 토큰은 녹색으로 표시되고 이미지 토큰은 파란색으로 표시됩니다.
Chameleon 주요 특징
전단 융합 토큰 기반 아키텍처
Chameleon 모델은 텍스트와 이미지를 전단에 융합하여 처리하는 토큰 기반 아키텍처를 채택하고 있습니다. 이는 기존의 모달리티별 인코더와 디코더를 사용하는 방식과 달리, 두 가지 모달리티의 데이터를 동일한 방식으로 처리할 수 있게 해줍니다. 이를 통해 모델의 유연성과 범용성을 크게 향상시킵니다.
안정적인 학습을 위한 혁신적 접근법
Chameleon 팀은 모델의 안정적인 학습을 위해 몇 가지 혁신적인 접근법을 도입했습니다. 여기에는 Query-Key Normalization(QK-Norm), 드롭아웃(Dropout), 그리고 z-손실 정규화(z-loss regularization) 등의 기법이 포함됩니다. 이러한 기법들은 모델이 다양한 데이터와 태스크에 대해 일관되게 학습할 수 있도록 도와줍니다.
텍스트와 이미지의 통합 처리
Chameleon은 이미지를 텍스트와 유사한 토큰으로 변환하여 처리합니다. 이를 통해 텍스트와 이미지가 혼합된 시퀀스를 자연스럽게 생성하고 이해할 수 있습니다. 이는 기존의 모달리티 분리 방식과 달리, 두 가지 데이터를 하나의 통합된 아키텍처로 처리할 수 있게 합니다.
2. 기술적 혁신
이미지 토큰화
Chameleon의 이미지 토큰화 과정은 512x512 이미지를 1024개의 토큰으로 변환합니다. 이는 8192-코드북을 사용하여 이루어지며, 텍스트와 동일한 방식으로 이미지를 처리할 수 있게 합니다. 이러한 접근법은 이미지와 텍스트 간의 연관성을 효과적으로 학습할 수 있게 합니다.
문장 조각(sentencepiece) 기반 BPE 토큰화
텍스트 토큰화는 문장 조각 라이브러리를 사용하여 65,536 어휘를 포함하는 BPE 토큰화 방식을 채택합니다. 이 과정에서 이미지 토큰도 포함되어 있어, 텍스트와 이미지가 혼합된 데이터를 효과적으로 처리할 수 있습니다.
안정적인 훈련 기법
Chameleon의 훈련 과정에서는 안정적인 훈련을 위해 다양한 정규화 기법과 드롭아웃을 사용합니다. 이를 통해 모델의 수렴성을 높이고, 대규모 데이터를 효율적으로 학습할 수 있습니다.
3. 성능 평가 및 비교
시각적 질문 응답
Chameleon 모델은 시각적 질문 응답 작업에서 우수한 성능을 보였습니다. 이 작업은 이미지와 텍스트를 통합적으로 이해하고, 질문에 대한 정확한 답변을 생성하는 것을 목표로 합니다. Chameleon 모델은 이 작업에서 기존 모델들을 뛰어넘는 성능을 발휘했습니다.
이미지 캡션 생성
이미지 캡션 생성 작업에서 Chameleon 모델은 최첨단 성능을 보였습니다. 이 작업은 주어진 이미지에 대한 설명을 텍스트로 생성하는 것을 목표로 합니다. Chameleon 모델은 다양한 이미지에 대해 정확하고 풍부한 캡션을 생성할 수 있었습니다.
텍스트 생성
Chameleon 모델은 텍스트 생성 작업에서도 우수한 성능을 보였습니다. 특히, 기존의 Llama-2 모델을 능가하는 성과를 거두었습니다. 이는 Chameleon 모델이 텍스트 데이터를 효과적으로 처리하고, 창의적이고 일관된 텍스트를 생성할 수 있음을 보여줍니다.
이미지 생성
Chameleon 모델은 이미지 생성 작업에서도 의미 있는 성과를 거두었습니다. 비록 전문적인 이미지 생성 모델에는 미치지 못하지만, 혼합 모달 환경에서 텍스트와 이미지를 통합적으로 이해하고 생성할 수 있는 능력을 보여주었습니다.
장기 혼합 모달 생성
장기 혼합 모달 생성 작업에서 Chameleon 모델은 인간의 판단 기준으로 기존의 Gemini Pro와 GPT-4V 모델을 뛰어넘는 성과를 기록했습니다. 이 작업은 텍스트와 이미지를 혼합하여 길고 복잡한 내용을 생성하는 것을 목표로 합니다. Chameleon 모델은 이 작업에서 우수한 성과를 보이며, 다양한 모달리티를 효과적으로 통합할 수 있음을 입증했습니다.
4. Chameleon의 기여
통합 모델링
Chameleon은 텍스트와 이미지를 동시에 처리할 수 있는 통합 모델링을 실현했습니다. 이는 두 가지 모달리티의 데이터를 별도로 처리하는 기존 방식의 한계를 극복한 것입니다.
새로운 평가 방식 도입
Chameleon 팀은 혼합 모달 장기 생성 평가를 통해 모델의 성능을 평가했습니다. 이는 기존의 정적 벤치마크 평가 방식의 한계를 극복하고, 실제 응용에서 모델의 성능을 보다 정확하게 측정할 수 있게 합니다.
멀티모달 상호작용 가능성 확대
Chameleon은 멀티모달 상호작용의 새로운 가능성을 열었습니다. 이미지와 텍스트가 혼합된 데이터를 자연스럽게 처리할 수 있어, 다양한 응용 분야에서 새로운 가능성을 제시합니다.
5. 결론
Chameleon은 혼합 모달 전 융합 모델의 새로운 가능성을 제시한 혁신적인 모델입니다. 다양한 태스크에서 뛰어난 성능을 보여주며, 통합 모델링의 혁신적 접근법을 통해 멀티모달 AI의 새로운 지평을 열었습니다. 앞으로 Chameleon의 성과와 발전 가능성에 주목해야 할 시점입니다.
Chameleon의 성공은 멀티모달 AI 모델의 발전 방향에 중요한 영향을 미칠 것으로 기대됩니다. 통합된 아키텍처와 혁신적인 훈련 기법을 통해, Chameleon은 다양한 분야에서 AI의 응용 가능성을 확장하고 있습니다. 이를 통해, Chameleon은 멀티모달 AI 연구의 중요한 이정표로 자리매김할 것입니다.
META, Chameleon Mixed-Modal Early-Fusion Foundation Models 발표 '인공지능' 카테고리의 다른 글
오픈AI, GPT-4o와 한국어 AI 생태계 글로벌 AI 기업과의 경쟁 (0) 2024.05.21 오픈AI, 장기적 AI 위험팀 해체 AI 안전성 문제 재조명 (0) 2024.05.18 AI 경쟁과 데이터센터 급증으로 인한 환경 문제 및 해결 방안 (0) 2024.05.18 구글, AI 에이전트를 탑재할 디바이스 구글 글래스 (0) 2024.05.17 텍스트 검색의 종말 AI 에이전트로 인한 마케팅 전략 변화 (0) 2024.05.16